- GRC Engineer
- Posts
- ⚙️ GRC Engineering isn't running parallel to security, it's running behind it
⚙️ GRC Engineering isn't running parallel to security, it's running behind it
Why building parallel GRC infrastructure wastes resources, alienates teams, and fragments authority across competing systems. Also, what to do instead!
Ayoub Fandi
September 04, 2025
IN PARTNERSHIP WITH

Streamline audits. Strengthen security.
GRC shouldn’t just be a checkbox. Done right, it’s a strategic advantage. Discover how leading security teams at PathAI and Druva are using workflow automation to accelerate audits, improve policy enforcement, and reduce manual effort.

What’s going on? 🔊
A couple of fun updates!
Just dropped this Tuesday this first ever GRC Engineer Deep-Dive with Pierre-Paul Ferland, GRC Senior Manager at Coveo.
Feedback so far has been amazing, some comments from readers:
🔥 This is great. I like the format and level of detail
🔥These deep dives are really interesting. Thanks for posting!
🔥 PP is a pro of the highest degree 😎 This was an awesome read!
Looking forward to running one every month with different GRC programs from across industries and get an insider view on GRC Engineering in practice. Some teams already reached out to be featured, feel free to reply to the email if you’re interested 🙂
Announced yesterday I’ll have Pete Waterman, the Director of FedRAMP, on the GRC Engineer Podcast!
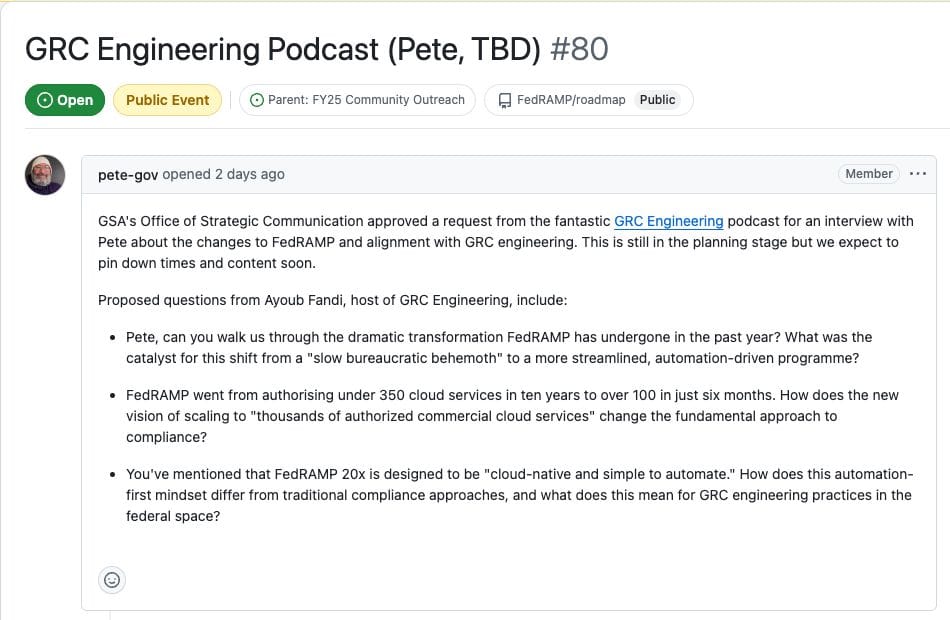
Super excited to chat with him about all the changes happening with FedRAMP 20x and how GRC Engineering has been embedded into the new approach to Federal compliance for CSPs.
When it drops, you’ll be the first to know 😉
Surprise podcast drop this weekend with one of the grc.engineering manifesto co-author.
Can’t say much more for now but it’s the first freeflow podcast conversation I’ve done. Really looking forward to y'alls feedback on it. Make sure you’re subscribed to not miss it!
For this week

Why GRC Engineering shouldn’t reinvent the wheel 🔍
The new power GRC Engineering is giving teams can alienate your security colleague and create substantial inefficiencies.
Picture this.

Not this.
Armed with additional engineering capabilities, your GRC team just spent three months building direct API connections to AWS, created custom rego policies for the CI/CD pipeline, and pulling data from identity management system.
Meanwhile, your AppSec team already pulls this data into their DevSecOps pipeline. Your InfraSec team has CSPM dashboards. Your CorpSec team has EDR and MDM reporting. Your IAM team manages identity provider data and access analytics.
You've built parallel infrastructure to collect the same data that security teams already own.
You’re not doing GRC Engineering, you’re doing redundant work at scale.
Security already figured it out
Security teams have already solved the hard problems you're trying to recreate:
AppSec teams wrestle with SAST/DAST tool integration daily - they understand the production constraints, API limitations, pipeline speed tradeoffs and data quality issues.
InfraSec teams maintain CSPM platforms across multiple cloud providers - they've figured out the authentication, access controls, and monitoring requirements across multi-cloud deployments.
CorpSec teams manage EDR and MDM systems that track device compliance - they handle the endpoint management complexity you don't want to own or replace.
IAM teams maintain identity provider integrations and access analytics - they understand user lifecycle management, privilege escalation patterns, and access review workflows
When GRC builds direct integrations to source systems, you're duplicating work whilst missing the context that security teams provide through their operational experience.
The Wheel already exists

Instead of going around security teams, work through them:
Pull AppSec data from existing DevSecOps reporting rather than rebuilding vulnerability collection
Leverage CSPM insights rather than creating parallel cloud monitoring
Use IAM team analytics for access reviews rather than building separate identity monitoring Feed security team outputs into your GRC data repository
As I mentioned in the policy-as-code analysis, security team alienation fragments authority across competing structures. The solution isn't building better technical integrations - it's building better team relationships that leverage existing security infrastructure.
One integration point. Established data pipelines. Proven production reliability.
You can potentially cover tens of thousands of entities in one go and share 100% of the security context at the same time.
In upcoming newsletter entries, we’ll work through the different personas and how they collaborate with GRC, we’ll go through for each of them:
Role research and technical domain understanding
Tech stack analysis and tool landscape mapping
GRC interaction pattern documentation
Control ownership mapping across different environments
Risk relationship analysis
Resource curation for further learning
Stay tuned for these!

Which persona do you want to be featured first? |

Community Highlights 🫂
Discussions coming from last week’s entry
Policy-as-code, feedback from readers
One issue I run into is that even the control owners are often managing only the “underlying” parts. Like the DBA team or the platform teams have internal customers, so even them don’t know about the policies that are enforceable. It’s often hard to pinpoint who owns the remediation, and automated remediation breaks stuff which is almost always unacceptable (availability is still in the CIA triad right?). It can be even worse because often you’ll have components built by people who left the company and no pay wants to own these legacy services… a lot of my buy bias comes from seeing how much devs hate maintenance work… and I work at a place that doesn’t incentivize necessarily NEW products and releases like Google does.
“PaC is very general. We enforce it with whatever we want not just one language. Bash, python, rego, kyverno, AWS scp, .... It's also spread throughout the SDLC (from pre commit to runtime) and I love it. Not just for security but mistake prevention - which couples really well with AI tools to make sure it doesn't make critical mistakes. That combined with context engineering is 🔥”
A GRC Engineer should not be getting alerts for anything that the control owner, who is actually responsible for the control, is not getting. Remediation in infrastructure or application control drift is not ambiguous, its always been on the control owner.
My experience been that it's best to leave policy as code development to actual DevOps/Engineering teams, but have visibility/insight into reviewing them and understanding what the policies accomplish and how they are written. This way you still have independence (since you didn't write the actual policy), yet you are technical enough to understand how policy is written, what it's doing and how it's operating.
My experience implementing automated compliance with Rego was one of the more lengthy projects I've undertaken in an organization.
Reading examples from the documentation is fun and all but if you get down to actually customizing it for different components in your stack it gets dirty quickly
What I’ve taken away from it
Consensus from GRC leaders, practitioners and engineers working at larger organisations is that it’s probably better to leave the syntax and overall implementation to specialist teams.
The GRC value-add is in setting the right requirements, monitoring (potentially through the existing DevSecOps toolchain) and ingesting those data points to feed back into GRC activities like control testing, risk assessments or improve granularity of security policies.

What I’ve been reading 📚
Resources I’ve been consuming which are relevant to GRC Engineering!
Sharing a newsletter that I think is a must-follow

I don’t often pay for newsletters but when I do, it’s called Scarlet Ink. This newsletter has been a staple for me for years and has been invaluable in my career. This post really really ties in into how GRC Engineering plays out and how to leverage the right type of impact to further your career.
Ex-Amazon General Manager Dave Anderson breaks down why "working hard" doesn't lead to promotions - you need to create scope beyond your assigned work to demonstrate next-level capabilities. His framework identifies three opportunity areas: highest organizational priorities, consistent unsolved problems, and continual operational costs. The key insight: you must free up 50% of your calendar to identify and pursue high-impact initiatives rather than adding promotion work on top of existing responsibilities.
Anderson's examples demonstrate career advancement through proactive problem-solving rather than task completion. The engineer who volunteered for launch-blocking bugs during organizational crisis, the designer who analyzed customer feedback to drive product improvements, and the developer who eliminated team inefficiencies all created value beyond their job descriptions. The pattern reveals that promotion comes from identifying business problems and taking ownership of solutions, not from executing assigned work more efficiently.
The framework applies broadly to professional advancement in any technical field. Rather than waiting for managers to define career development opportunities, successful professionals create their own advancement paths by identifying organizational pain points and building solutions that demonstrate next-level thinking. This proactive approach transforms career development from manager-dependent process to self-directed strategic initiative.
Read the full post (paywalled): Work Hard, Stay Busy, and Stay Exactly Where You Are

That’s all for this week’s issue, folks!
If you enjoyed it, you might also enjoy:
My spicier takes on LinkedIn [/in/ayoubfandi]
Listening to the GRC Engineer Podcast
See you next week!
Reply