- GRC Engineer
- Posts
- ⚙️ Why the Policy-as-Code revolution didn't happen (and what can we do?)
⚙️ Why the Policy-as-Code revolution didn't happen (and what can we do?)
On the back of the news of the acquisition of the Styra team behind Open Policy Agent by Apple, we'll discuss how Policy-as-Code has been fitting into GRC Engineering and the way forward.
Ayoub Fandi
August 28, 2025
IN PARTNERSHIP WITH

Traditional DLP isn’t build for AI
While legacy tools focus on email, file transfers, and endpoints, AI platforms like ChatGPT introduce new risks that demand smarter safeguards.
Learn how leading enterprises are evolving their DLP strategies to embrace AI securely – without compromising compliance or control.

What’s going on? 🔊
Numerous people reached out this week and last around policy-as-code. Coming out of the acqui-hiring of Styra (company behind Open Policy Agent) by Apple.
There’s also a lot of founders pitching me on new solutions adjacent to Policy-as-Code for GRC team (including numerous YC-backed ones).
I’ve always geeked out on Policy-as-Code even in the Kubernetes context which is where the use-cases originated from.
In this week’s entry, I’ll dive a bit deeper on what’s the adoption like, what are the critical challenges for GRC teams and why in reality you shouldn’t care about specific technologies. You should care about GRC outcomes.
We’ll also have a look at the great write-up on control maturity written by the Reddit GRC team (who are long-time readers of the newsletter which I’m excited about!)
For this week

Policy-as-Code, where are we? 🔍
Why Policy-as-Code has had limited success in GRC in the last 8 years
Everyone's talking about Policy as Code, it’s been a GRC buzzword for some time! It’s almost synonymous to GRC Engineering at this point (even though the manifesto states it’s not GRC + Code)
You see your policies in PDFs, Word docs, Confluence pages and markdown files and you're thinking… “I could write policy in actual code, write policy-as-code, that’s the future right?”
Not getting into the details of what a policy should actually be, let’s peel the onion on Policy-as-Code but learning more about Open Policy Agent.
What is OPA?
Open Policy Agent (OPA) is a policy engine that lets developers write authorization rules in a language called Rego and apply them consistently across microservices, Kubernetes, and cloud infrastructure. It was built to solve the problem of organizations having hundreds of systems with different authorization approaches, providing unified "who can do what" decision-making across diverse technical environments.
What is adoption looking like in its core domains?
Poll data from late 2023 on the Kubernetes subreddit reveals a striking disconnect: in a poll of 509 practitioners, only 26% actually use Open Policy Agent in production, whilst 53% explicitly reject it and 21% remain stuck in planning phases.
If three-quarters of Kubernetes professionals, the exact audience OPA was designed for, can't or won't implement OPA, what does this mean for GRC practitioners facing even steeper barriers?
What are practitioners saying?
The community discussions reveal why infrastructure engineers abandon policy-as-code implementations:
"Our team literally switched off rego because the overhead of learning it was too much to justify over other options" - DevOps practitioner with 3+ years experience
"We gave up and switched to Kyverno... no one wanted to maintain [Rego policies]" - Kubernetes administrator
"The Rego language is a bit of a pain to learn... what a pita it is" - Infrastructure engineer
These aren't non-technical users struggling with basic concepts. These are infrastructure engineers, DevOps practitioners, and Kubernetes experts working in product environments who find Rego "ridiculously confusing" despite having programming backgrounds and eating YAML for breakfast.
What about for GRC professionals then?
When technical practitioners struggle this significantly, the coordination challenges compound exponentially for GRC teams:
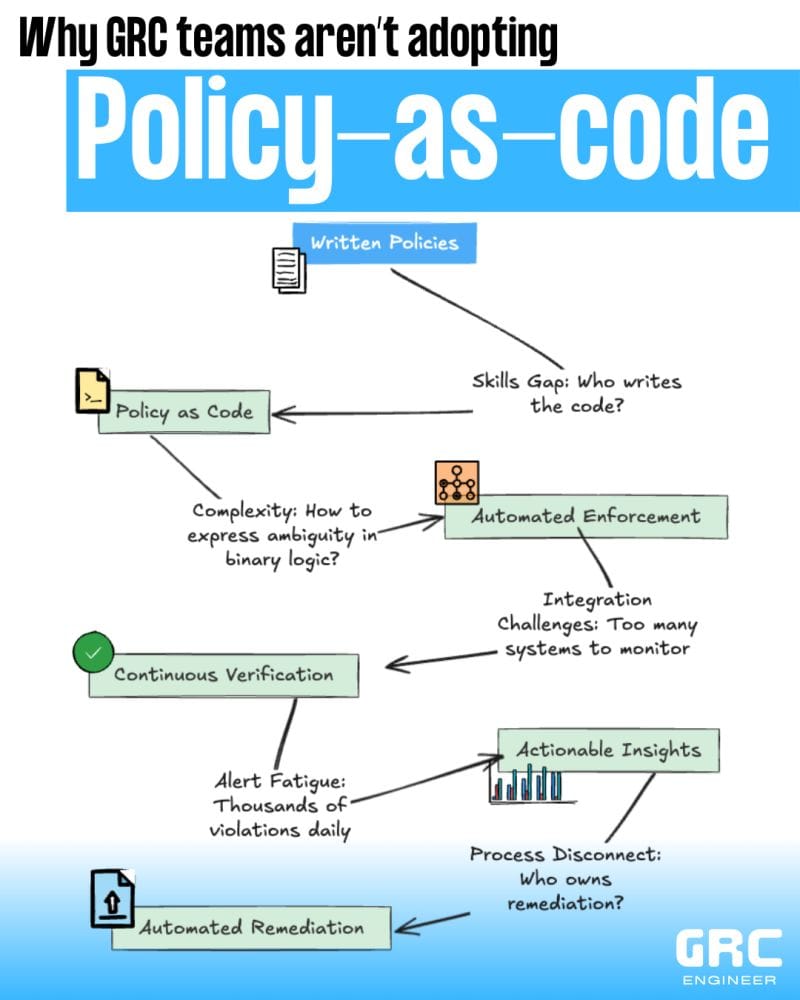
Stage 1: Written Policies → Policy as Code "Just code your policies!" But who writes them? Your compliance analyst with the CISSP and zero Python experience? DevOps practitioners note that "writing even a single policy takes a lot of effort" and "policies aren't re-usable." If experienced engineers find policy creation cumbersome, GRC teams face insurmountable barriers.
Stage 2: Policy as Code → Automated Enforcement
"Make it executable!" Right, because "ensure appropriate security measures based on risk" translates to deterministic logic. The gap between governance language and code logic creates what I’ve described as GRC’s abstraction problem.
Stage 3: Automated Enforcement → Continuous Verification "Monitor everything!" One practitioner's microservices authorization challenge highlights the integration nightmare: "We're encountering difficulties with efficiently handling the dynamic data, particularly due to frequent restarts in our Kubernetes environment."
Stage 4: Continuous Verification → Actionable Insights "See all violations!" Even technical teams struggle with policy maintenance. As one developer noted: "We have a huge library for k8s validation and mutations, but at some point no one wanted to maintain them." How a GRC team that struggles to cross-reference compliance and risk data can handle this volume?
Stage 5: Actionable Insights → Automated Remediation "Auto-fix everything!" The automation promise breaks down when policies need constant technical maintenance that neither GRC teams nor engineering teams want to own. Anyone that tries to automate remediation in production environments outside startups knows exactly what I’m talking about.
Those 5 stages lead to 4 major limitations
Let’s think through what GRC teams should be doing and understand the role of Policy-as-Code in that context:
Independence Erosion
GRC teams lose oversight objectivity when they become responsible for implementing the technical systems they're supposed to assess independently. Control enforcement and control assessment represent conflicting organisational functions. It’s often pushed to the side but it undermines the actual concept of GRC.
Coordination Bottlenecks
Policy automation forces GRC teams to become technical intermediaries between business requirements and engineering implementation, creating workflow dependencies rather than reducing them. The pool of GRC individuals who will able to maintain them is so small you end up with strong single-point-of-failures.
Opportunity Cost Explosion
GRC teams can't do everything. Strategic work whilst maintaining technical infrastructure is tough when you also maintain scripts, your GRC tool, touchpoints with custom systems, etc. This economic argument resonates with executives evaluating resource allocation and determining the ROI of implementing Policy-as-Code
Security Team Alienation (the worst one)
It is a critical political problem created by Policy-as-Code initiatives led by the GRC team - it fragments security authority across teams rather than building collaborative relationships. If the cloud security team or the application security team have chosen a better approach for what they want to accomplish, work with them instead of chasing specific technologies over GRC outcomes.
What should I do then?
The difference between policy-as-code demonstrations and enterprise implementation reflects broader systemic challenges. Simple examples work well in controlled environments, but enterprise policy automation requires handling exceptions, legacy systems, organisational politics, and constantly changing business requirements that resist encoding into deterministic logic (for now…)
The way forward?
Work with your security team, they know exactly the tech stack, the current security scanning and checks built-in, be it IaC scanning or SAST. Try to pull from these to enrich your data vs. trying to replace it with something worse.

What's your organisation's current policy-as-code status?I will share the results next week! |

What I’ve been reading 📚
Resources I’ve been consuming which are relevant to GRC Engineering!
Reddit's Control Maturity Journey
Amazing team members from the GRC team at Reddit (Miranda Kang, Sid Konda and Michael Rohde who’s leading the team) have authored a write-up and how they matured their approach to security controls.
They used a very scientific method to demonstrate their new approach to GRC:
Reddit + GRC = Security Controls + Compliance
Reddit + GRC x (GRC)Engineering = Control Maturity + Strategic Innovation
Who am I to disagree with that?
I’ve enjoyed this detailed breakdown of their four-year GRC transformation that demonstrates what systematic control evolution actually looks like in practice. A couple of things I’ve found interesting:
Their progression from spreadsheets to a dedicated tool to selective automation shows the central data layer approach working in real enterprise environments. Most significantly, their 40% control reduction through common controls mapping is a systematic harmonisation that creates more efficiency compared to adding frameworks incrementally. Managing controls at scale is often where a GRC tool can become a game-changer.
Reddit's automation choices reveal strategic discipline: training completion enforcement, evidence collection scripts, and log review automation. They focused on reducing stakeholder friction through process improvement rather than pursuing comprehensive technical automation requiring constant maintenance from GRC teams.
Their approach demonstrates the GRC product mindset in action - prioritising control effectiveness and stakeholder experience whilst using automation to enhance rather than replace governance judgement. The four-stage maturity model they present (ad hoc → defined → automated components → fully automated) emphasises process standardisation before technical implementation.
Everyone should also build a way to think about prioritisation where to focus maturity efforts, I love theirs:
Potential for failure (Is it highly complex, or requires judgment that may lead to inaccuracies?)
Stakeholder Level of Effort (Does it take a long time? Think of the opportunity cost!)
Low hanging fruit (Is it something we could quickly automate and get buy-in for future work and start showing returns?)
Things we don’t want to do
Overall, it’s a must-read.
Looking forward to getting them on the newsletter/podcast to share more (if you’re listening 😉)
Read the full Reddit post: Houston, We Have a Process: A Guide to Control Maturity

That’s all for this week’s issue, folks!
Let me know what you think of this new setting/format for the newsletter, really looking forward to y’alls feedback 🙂
If you enjoyed it, you might also enjoy:
My spicier takes on LinkedIn [/in/ayoubfandi]
Listening to the GRC Engineer Podcast
See you next week!
Reply