- GRC Engineer
- Posts
- ⚙️ Your Certification Covers 100%. Your Auditor Checked 0.07%.
⚙️ Your Certification Covers 100%. Your Auditor Checked 0.07%.
The math behind compliance assurance does not work the way you think it does. Why moving at agentic speed means rebuilding the primitives of what GRC Engineering has to cover.
Ayoub Fandi
March 24, 2026
Your auditor tested a sample of 25 out of 24,000. Your board saw a clean SOC 2 report. Your attacker saw 23,975 occurences nobody looked at.
All three are telling the truth.
This is the sampling extrapolation problem. It is the structural flaw at the centre of every certification your customers trust, every badge on your website, and every compliance program built to satisfy an audit rather than reduce risk.
Other security disciplines sample too. Pen testers scope engagements. Vulnerability scanners prioritise targets. But none of them issue a pass/fail certification on the back of that sample. Only GRC does that. Only GRC takes a partial observation and stamps it as comprehensive assurance.
That distinction matters. Sampling is a tool. Certifying on the basis of a sample is a claim. And the claim does not hold.

IN PARTNERSHIP WITH

Forrester says AI Agents will transform GRC from manual tasks to automated workflows
Forrester’s Q4 2025 GRC Platforms Landscape lays out the playbook: integrate assurance into pipelines, automate evidence, enable continuous validation, and deploy AI that acts (not just chats). Scrut was featured among the 30 vendors in the report. See how Scrut Teammates was built to execute compliance busywork, with human-in-the-loop.

Where Sampling Comes From
The methodology was borrowed from financial auditing. In finance, it works.
Financial fraud is systemic. If someone is cooking the books, the pattern shows up across transactions, quarters, and accounts. Sampling catches it because the signal is distributed evenly across the population.
Security vulnerabilities do not work like that. They are focal. One misconfigured S3 bucket. One unpatched dependency. One forgotten test environment with production credentials.
An attacker does not need a pattern. They need an entry point.
The statistical term is population homogeneity. Financial transaction populations are structurally similar. Every purchase order behaves like every other purchase order relative to fraud. Security controls are the opposite. A firewall rule does not behave like an access review, which does not behave like an encryption configuration.
Sampling theory (ISA 530, AU-C 530) requires homogeneous, stratified populations for valid inference. Most GRC audits do not stratify at all. They sample across fundamentally different control types and extrapolate as if the population were uniform.
We borrowed the right technique from the wrong domain. And nobody validated the transfer.

The Three Circles
Think of your environment as three concentric circles.
Circle | What it represents | Example |
|---|---|---|
Inner | What your auditor actually sampled | 5 controls, 10 systems, 25 PRs from a 12-week observation window |
Middle | What your certification claims to cover | Your entire trust services criteria scope, all controls, all systems |
Outer | Your actual attack surface | Shadow IT, third-party APIs, cloud resources engineering provisioned without telling GRC |
Your SOC 2 badge spans all three circles. Your auditor only looked at the inner one. The attacker only needs access to the outer one.
Let me put concrete numbers on this. Say your engineering team ships code 100 times a day. Over a 12-month SOC 2 reporting period, that is roughly 36,000 pull requests. Your auditor samples 25 of them.
That is a sample rate of 0.07%.
The same 25 gets pulled whether the population is 200 or 200,000. The joiners, movers, and leavers process? Sampled. Specific endpoints? Sampled. Merge requests? Sampled. The number 25 does not change. The population it represents does.
In statistical science, a sample of 25 from a population of 36,000 is not statistically significant for heterogeneous populations. But we certify the whole company against it.
Now consider: SOC 2 reports do include scope limitations. But the badge exists precisely because buyers do not read reports. How many RFP processes accept "SOC 2 Type II: Yes/No" as a checkbox? The same dynamic applies to ISO 27001, where the scope can be manipulated to cover a narrow slice of the actual environment. People outside your organisation do not know what is specifically in production. They trust the badge.
The gap between the inner circle and the outer circle is not a rounding error. It is the difference between what your customers believe and what is actually true.
IN PARTNERSHIP WITH

Why FedRAMP Is About to Matter to Every GRC Team (Even If You Don’t Sell to the Government)
Compliance doesn't have to suck.
Stop drowning in "soul-crushing" spreadsheets. Whether you’re tackling FedRAMP 20x, Rev 5, or CMMC, Paramify automates the heavy lifting. Generate instant, machine-readable SSPs and POA&Ms that are actually audit-ready.
Get compliant 90% faster at 1/4 the cost - and like your job at the same time.
The Incentive Machine
Sampling does not just produce weak assurance. It produces perverse incentives.
When your audit methodology rewards a smaller sample, teams learn to limit scope artificially. Fewer systems in scope means fewer findings. Fewer findings means a cleaner report. A cleaner report means less remediation work.
Your risk programme starts optimising for a smaller audit surface instead of a stronger security posture.
I see this constantly. Engineering builds new services. GRC negotiates to keep them out of scope until the "next audit cycle." Shadow infrastructure grows in the outer circle while the inner circle stays tidy and certifiable.
The audit becomes a game of containment. Not "how secure are we?" but "how small can we make the thing the auditor looks at?"
There is also a liability dimension nobody discusses. Auditors prefer sampling partly because a defined methodology limits their professional liability. If they sample correctly and miss something, the methodology protected them. Full-population testing would actually increase their exposure. The incentive to keep sampling is structural on both sides of the engagement.
Meanwhile your AppSec team chases full coverage across the codebase. Your cloud security team scans every workload. And your GRC programme celebrates a clean sample of 25 pull requests out of 36,000.
You are operating in different realities. And the audit methodology is why.
The Agentic Acceleration
This problem is getting worse, not better.
The data is stark. zerodayclock.com from Sergej Epp tracks 3,520 CVE-exploit pairs from trusted sources (CISA KEV, VulnCheck KEV, XDB). The mean time-to-exploit has collapsed from 2.3 years in 2018 to 1.3 days in 2026.
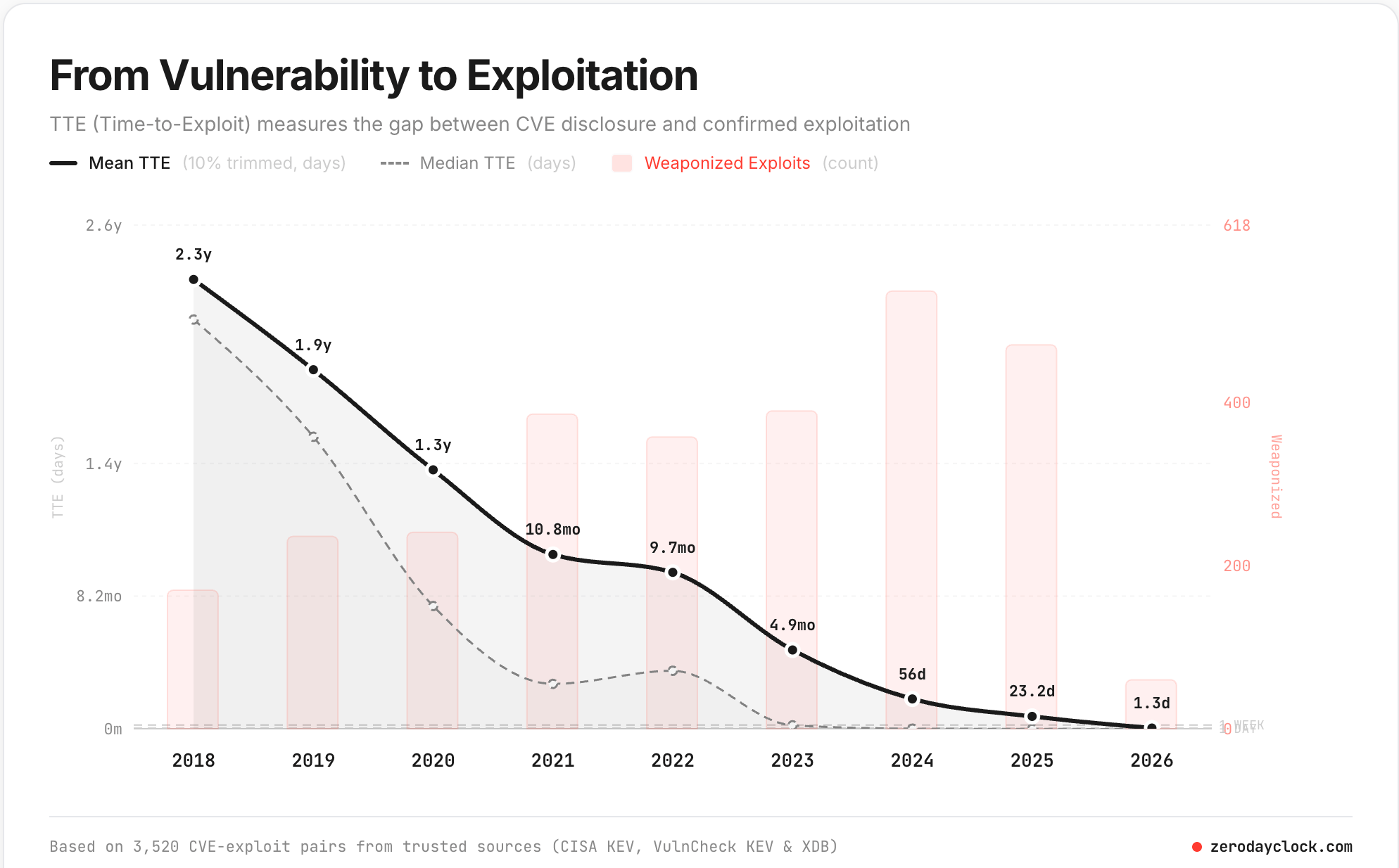
The milestones tell the story. Mean TTE crossed the 1-year threshold around 2021. It crossed 1 month in 2025. It crossed 1 week in 2026. The 1-day and 1-hour thresholds are projected for later this year.
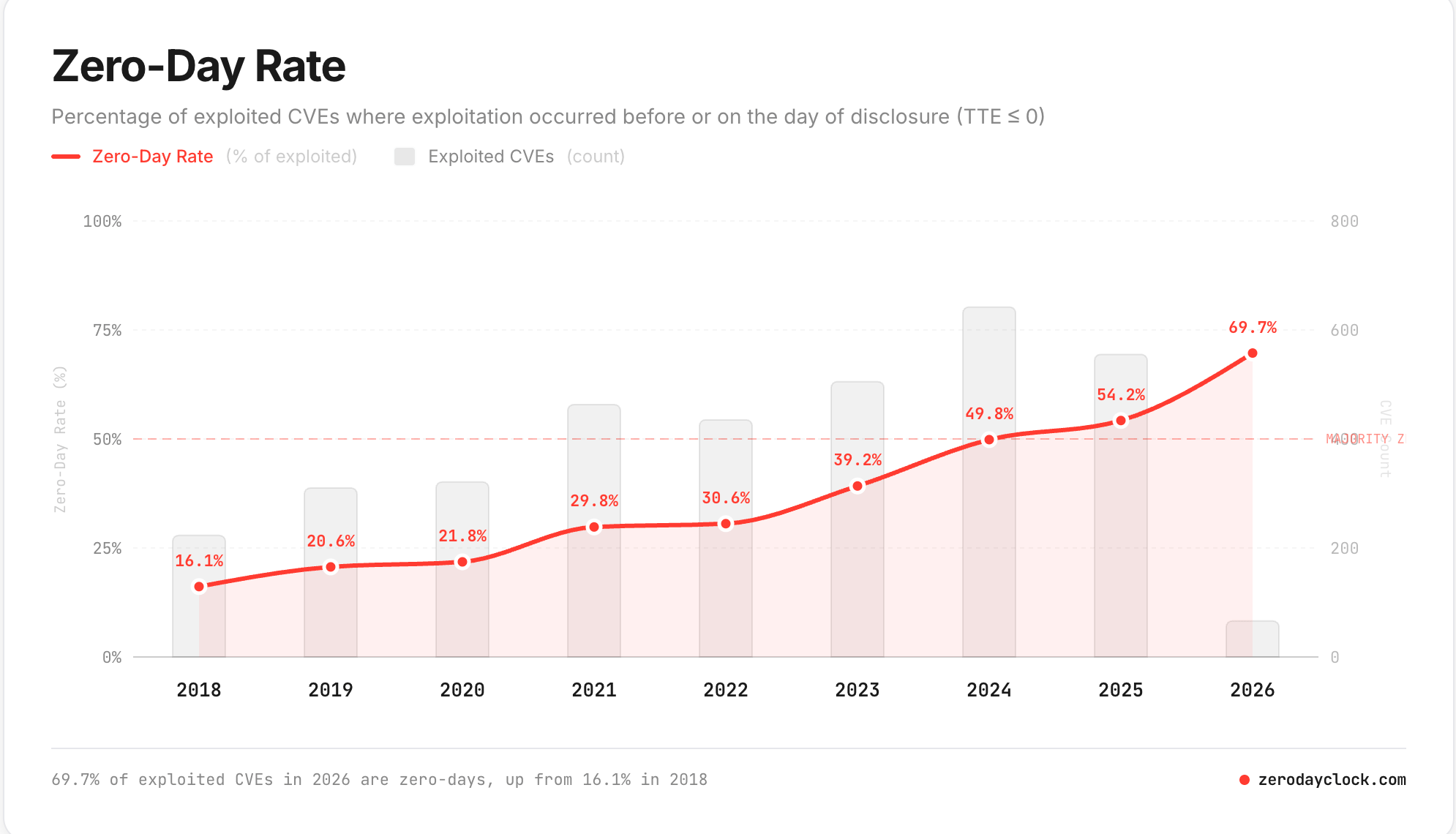
And the zero-day rate is accelerating. In 2018, 16.1% of exploited CVEs were weaponised on or before disclosure day. In 2026, that number is 69.7%. Nearly seven out of ten exploited vulnerabilities are compromised before or on the day they are publicly known.
Look at the exploit survival curve. On Day 0 after disclosure in 2018, 83.9% of CVEs were still unexploited. In 2026, only 30.3% survive Day 0. The traditional 30-day patch window is gone. The curves are collapsing leftward, year over year.
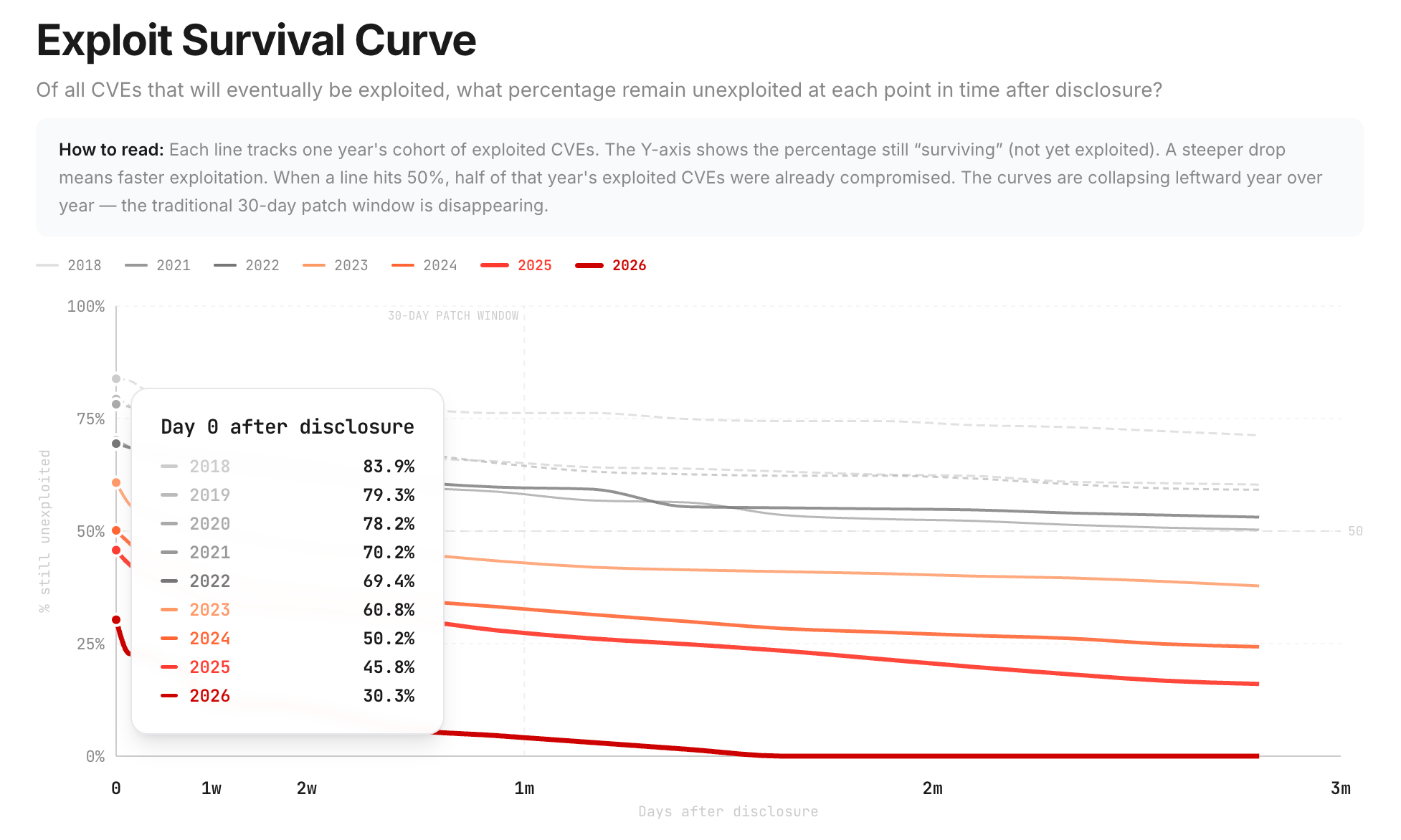
Your quarterly audit cadence was designed for a world where threats moved in months. That world ended years ago. The observation window is now measured in hours.
Whatever assurance we provide is based on a legacy trust model. We trust the auditor. We trust the methodology. But the fundamental design of the audit process breaks when you check an extremely small, statistically insignificant sample while the threat landscape moves at machine speed.
Let’s be real. If the CISO looks at this data and then looks at what GRC produces, and the answer is "we sampled 25 controls and everything passed," we have made ourselves irrelevant. The security org will route around us. They will build their own risk tracking, their own coverage dashboards, their own threat-informed prioritisation. And they will be right to do it.
GRC stays relevant by speaking the language of threats, not just the language of audits. The zerodayclock data is not someone else's problem. It is the context in which our controls either matter or do not. If we cannot connect our assurance to the threat landscape, we are just producing paperwork.
One unpatched box in the 98% your auditor did not check will not show up in any confidence interval. But it will show up in your incident response plan.
What Replaces Sampling
The answer is not better sampling. It is abandoning sampling for continuous, exhaustive, machine-verified evidence.
This was impractical in 2005. It is not impractical now.
Every control that matters emits telemetry or is queryable via API. Access reviews can run continuously. Configuration checks can execute every hour. Evidence collection can cover the full population, not a curated subset.
The argument that 100% testing is impractical may have been true a decade ago. The tooling has matured. The costs have dropped. The persistence of the argument after those changes deserves scrutiny.
For organisations running multiple compliance frameworks, continuous evidence platforms cost less than annual audit fees within 18 months. The real comparison is not "automated exhaustive testing vs manual exhaustive testing." It is "automation platform vs audit fees in perpetuity."
GRC engineering makes this real. Instead of sampling 25 PRs and hoping they represent 36,000, you build a pipeline that validates every PR against your control criteria. Instead of spot-checking access reviews quarterly, you run them weekly across the full population.
The inner circle expands until it meets the outer circle. That is what actual assurance looks like.

What To Do This Week
If any of this resonates, here is where to start:
1. Request your auditor's sample selection memo. Ask exactly how many controls were tested, out of how many total. Get the actual numbers.
2. Map your actual control population against what was tested. Count every system, every service, every cloud resource. Compare that number to what was in scope.
3. Present the delta to leadership as residual unverified risk. The gap between "tested" and "total" is not a technicality. It is your actual risk exposure that no badge covers.
4. Ask the uncomfortable question. If your certification only verified a fraction of your environment, what is the remaining unverified surface worth to your customers?
5. Start one continuous control. Pick a single control and automate evidence collection across the full population. See what you find when you stop sampling.
Did you enjoy this week's entry? |

That’s all for this week’s issue, folks!
If you enjoyed it, you might also enjoy:
My spicier takes on LinkedIn [/in/ayoubfandi]
Listening to the GRC Engineer Podcast
See you next week!
Reply